
貴社の顧客とユーザーは、御社アプリに生成AIを搭載するアナリティクス機能を期待しています。
Battery Ventures社の調査によると、回答企業はすでにAIと機械学習を採用しており、さらに全体の79%が今後12ヶ月以内に生成AI/大規模言語モデル(LLM)を利用する予定であると報告されました。
しかし、単に生成AIをアプリに追加することは解決策ではありません。結局のところ、それは本当の価値を提供しなければ意味がないからです。生成AIを自社製品のロードマップに組み込むことを選んでいるプロダクトリーダーや開発チームと話すと、彼らは一貫して同じ質問をしてきます。
- ・AIファーストの経験を通じて、ユーザーにどこが革新し、どのような価値が提供できるのだろうか?
- ・責任を持って提供し、ユーザーの信頼を損なう幻覚を避けるにはどうすればよいのか?
- ・大規模言語モデルをロックインすることによるリスクを回避しながら、迅速に提供するにはどうすればよいのか?
質問に対する答えは、多くのチームからすぐにでてきます。生成AIや大規模言語モデルが登場する以前から、ユーザーを惹きつける確実な方法は、アナリティクス機能を製品の一部として組み込むことでした。このような機能を有するアプリケーションは、有さないアプリケーションと比較して、ユーザーエンゲージメントが大幅に増加しているからです。
アプリ内でパーソナライズされたインタラクティブにデータビジュアライゼーションを提供するアナリティクスは、ユーザーエクスペリエンスを向上させ、エンゲージメントレベルを高めることができます。そして、今後より利便性を高めるために、会話型によるアナリティクスにシフトしていくでしょう。そのキーテクノロジーが生成AIとなります。
本記事では、アナリティクスと生成AIの交差する会話型アナリティクスの新時代が、自社アプリのロードマップに重大な影響を与える理由を学びます。
そして、会話型アナリティクスを組み込む際の5つのCについても共有します。これらは製品とAIの両チームが採用しようとする生成AIをいかに成功させるための一貫した新しいテーマと言えます。最後に、Sisense Compose SDKを利用し生成AIをどう拡張するのかについてお話しします。
会話型アナリティクスへの進化
会話型AIシステムと大規模言語モデルは、ユーザーからの問い合わせを理解し、文脈化することに優れています。これらにより、過去のやり取りやユーザーの履歴を活用して、質問者が求める適切なインサイトを提供することができます。従来のアナリティクスツールと比べて利便性が高まり、生産性を大幅に向上させることになりました。
さらに、チャット形式のインターフェースは、より直感的でユーザーフレンドリーとなり、ユーザーはAIと楽しく会話をしながら、必要な情報にアクセスすることができます。
これにより、ユーザーエクスペリエンスが向上し、ユーザーの学習曲線が短縮されることで、より多くの人にアナリティクスリテラシーが向上すると期待されています。
実際、エッカーソングループは、会話型ビジネスインテリジェンスを次のステップと見ており、前世代のビジュアルアナリティクスや検索ベースのBIツールを超えて、ユーザーがより取り組みやすくなると考えている。
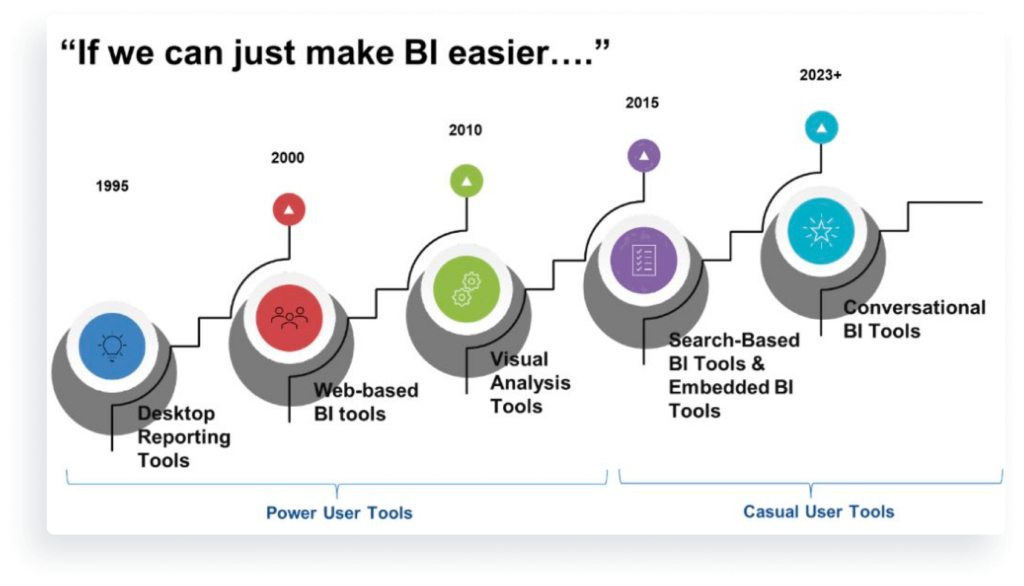
生成AIアナリティクスを組み込むための道筋
このアナリティクスの新時代を受け入れ、成功させるためには、プロダクトチームとエンジニアリングチームがたどる基本的な道筋があります。私たちはこれを「会話型アナリティクス5つのC」と呼んでいます。
1.会話と文脈(Conversational and contextual)
ユーザーが自分に関連するインサイトを素早く特定できるようにする。例えば、「国別の売上はいくらですか?」のような、データモデルに基づいた自然言語による分析開始プロンプトを提案することから始めます。「どの分野について質問できますか?」など、分析の範囲について回答するなど深掘りさせます。そして、会話の後半では「これらの結果について説明してください」といった説明的なガイダンスを提供し、文脈に沿ったフォローオンプロンプトを有効にするなど、質問の流れを作っていきましょう。
2.コンポーザブル(Composable)
会話型アナリティクスが自社アプリの見た目や使い勝手が異なる場合、採用するのが難しくなります。これを解決できるのが、コンポーザブル アナリティクス SDKです。開発チームに対し、ビジュアライゼーションからAIアナリティクスチャットボットまで、さまざまなReactコンポーネント(またはその他のフレームワーク)と、制御するためのTypeScript/JavaScript言語を提供します。コンポーザブル アナリティクス SDKは、製品チームがユーザーのために的確な会話とワークフローを構築することを可能にし、自然言語をより直感的な機能を提供できることを可能とします。
3.能力、責任、信頼(Capable, responsible, and trusted)
大規模言語モデルとの関わり方や場所に関係なく、信頼は最も重要です。会話型アナリティクスの場合、信頼を確保する基本的な方法は、セマンティックレイヤーまたはデータモデル上に構築することです。これにより、アナリティクス開発チームは、エンドユーザーの分析エクスペリエンスが包含するスコープ、意味、フィールド、および関係を定義することができるようになります。
もう1つの重要な検討事項は、データ、プロンプト、および出力に対してどのような管理が行われているかです。例えば、大規模言語モデルモデルの改善やトレーニングに使用されるのか、あるいはその他の方法で共有されるのかなどとなります。
4.クラウドと大規模言語モデルにとらわれない(Cloud and LLM agnostic)
AIは常に変化し続けます。そのため、会話型アナリティクスを組み込む場合、1つの大規模言語モデルにとらわれないことが重要となります。その理由は、今利用している大規模言語モデルが将来、最適ではなくなるかもしれませんし、コンプライアンスの必要性から、独自のプライベート大規模言語モデルへ移行することがでてくるかもしれないからです。 つまり、OpenAI GPT 3.5からGPT-4、Anthropic/Claude、Bard、LLaMaの利用であろうと、独自のプライベート大規模言語モデルの利用(または単に独自のプライベートOpenAIインスタンス)であろうと、クラウドと大規模言語モデルにとらわれないことが重要と言えます。
5.コスト(Cost)
最後に、大規模言語モデルの検討する際には、コストについて議論することも重要です。
パブリックモデルから社内モデルまで、さまざまな大規模言語モデルをプラグ&プレイするため、コスト管理に柔軟性が必要となります。使い方による大規模言語モデルのコスト増減や、AIプロバイダー間の進化に伴い、費用をコントロールする必要が出てくるからです。言うなれば、バランシング、スケーラビリティ、手頃な価格、そして出力品質を管理することで、最も費用対効果の高い大規模言語モデルを的確におさえることにつながるからです。
Sisense Compose SDKに生成AIアナリティクス機能が追加
ソフトウェアエンジニアや開発者が、ReactやTypeScriptなどの最新のフレームワークや好みの代替手段を利用して、Sisense Fusionの分析機能を任意のWebアプリケーションに埋め込むことが容易にできるように、今年初めにCompose SDKを発表しました。このSDKにより、開発者は特定のニーズに合わせて柔軟で汎用性の高い方法で分析を追加できます。
現在、Sisense Compose SDKは拡張し続け、エンジニアが生成AIアナリティクスを自社製品、ユーザーエクスペリエンス、ワークフローに対して、容易に組み込めます。
アナリティクス・チャットボットについて
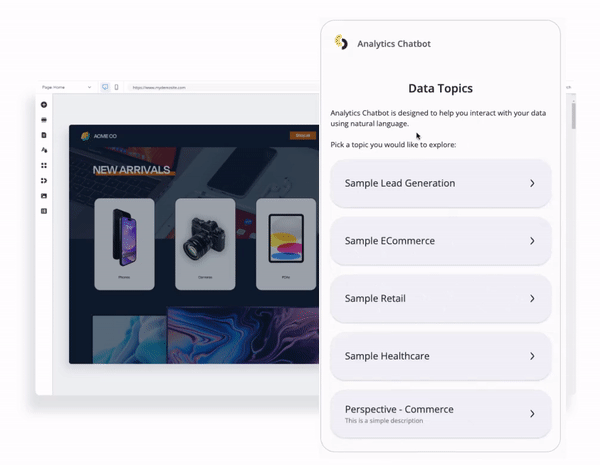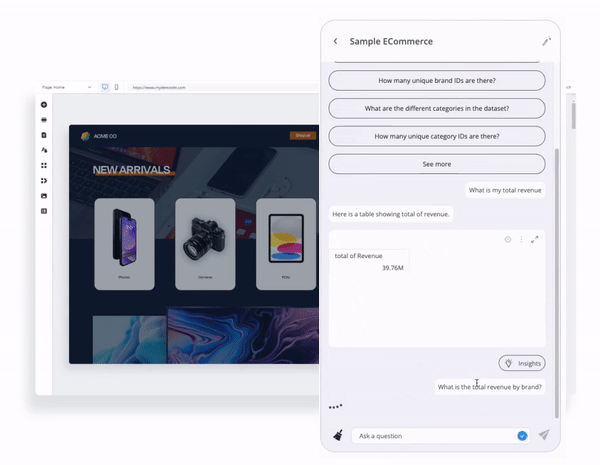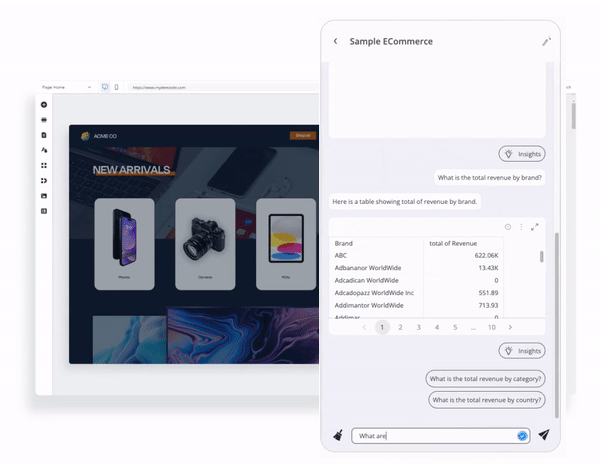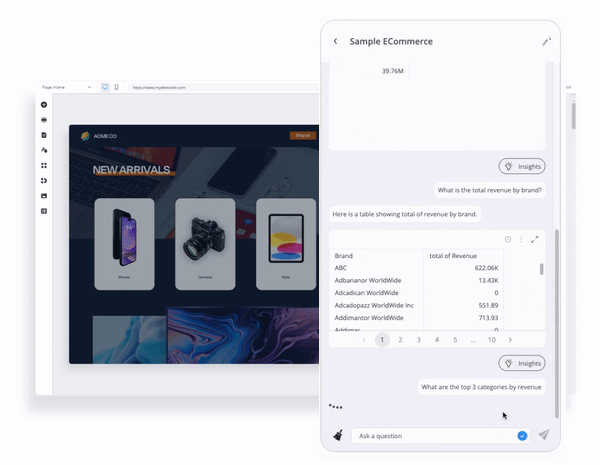
生成AIアナリティクス機能を自社製品に導入できます。アナリティクス・チャットボットは、組み込むことができる大規模言語モデルの相棒となります。これは、Reactコンポーネントとして提供され、ユーザーが事前に生成されたQuickStart自然言語の質問で会話を始めることができます。
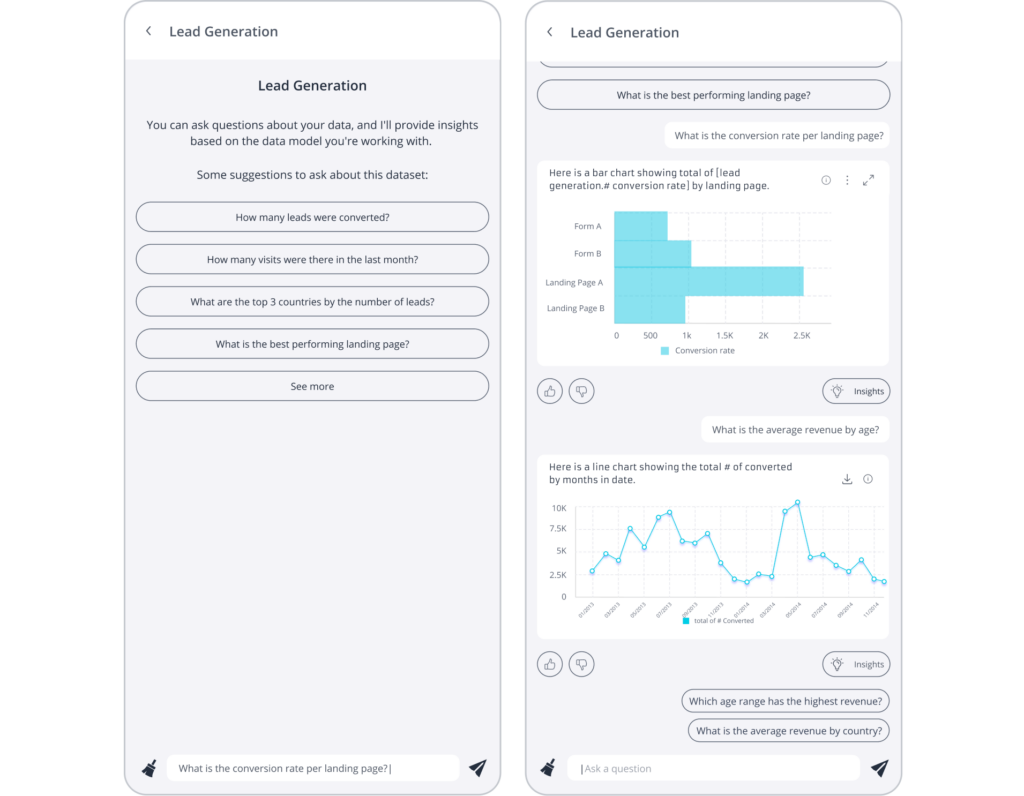
アナリティクス・チャットボットを使用すると、ユーザーがクエリできるフィールドやメトリクスなど、データモデルに関する質問や分析の質問をすることで視覚的な回答を得たり、結果に基づいてデータストーリーテリングの詳細なナラティブを生成したりできます。
さらに良いことに、アナリティクス・チャットボットはは完全に「コンポーザブル」です。チャットボットがどのように機能するかは、開発者の幅広いユーザーエクスペリエンスによってコントロールできます。そして、開発チームは、アプリの他の部分と組み合わせて利用しながら、機能拡張やカスタマイズを行うことができます。
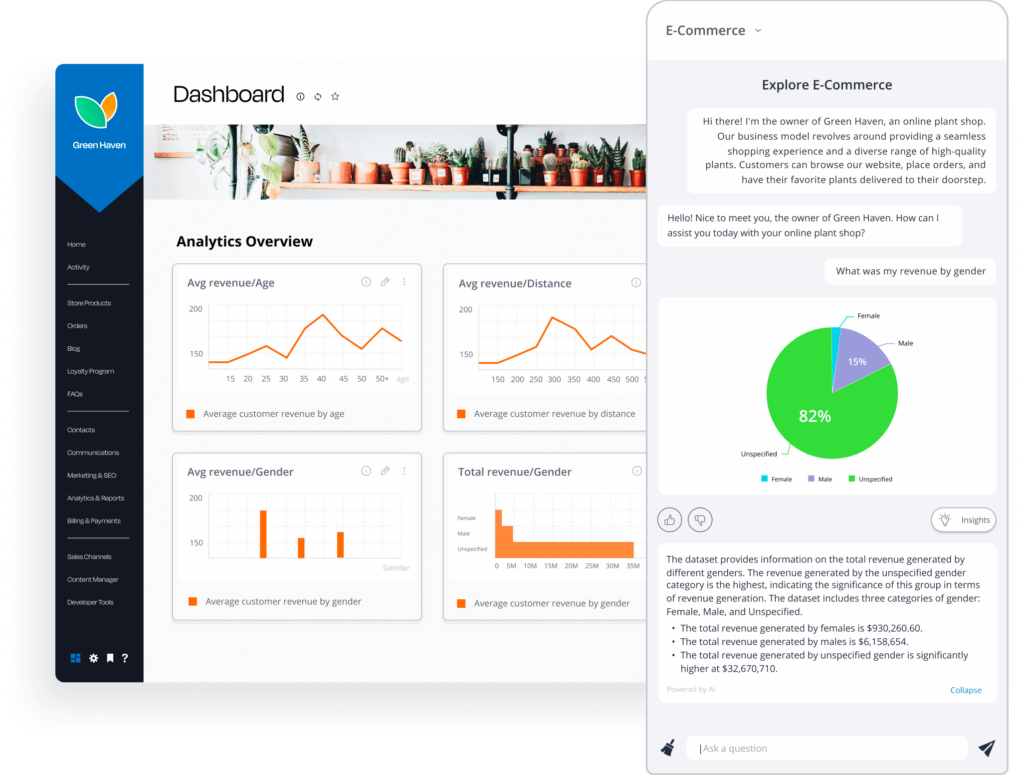
ナラティブ生成AIでユーザーが簡単に答えを解釈できるようになる
もし、自社アプリがユーザーに分析結果を説明できるとしたらどうでしょうか?Compose SDK React Componentのナラティブ生成AIを使えば、それが可能になります。ナラティブにより、ユーザーは簡単にデータセット内の重要な発見をテキストで説明することができます。
これらの説明は、自然言語生成技術を使用して生成され、高度なアルゴリズムによってサポートされ、インサイト、傾向、異常を強調する明確で簡潔なストーリーを生成します。このナラティブは、ヘッドレスで使用するためのCompose SDK内のAPIとしても利用できます。
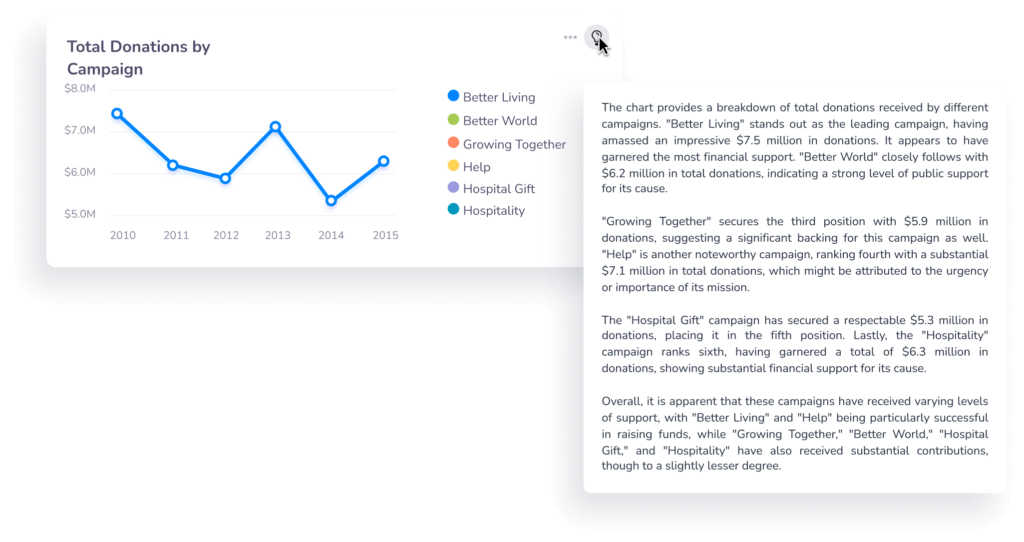
レゴブロックのようなコンポーザビリティにより会話をコントロール
Compose SDKはゼロから構成できるため、QuickStartの質問、ナラティブ、データトピック(ユーザーが会話するデータモデルを選択できるようにする)など、すべての会話が個別のReactコンポーネントとして利用できます。そして、もちろん、生成AI搭載の分析をアプリケーションを組み込みたい場合もすべての機能はAPIとして利用できます。
信頼できる責任ある開発のための設計
自社アプリから得られる生成AIを利用したアナリティクスの答えに自信を持ってユーザーが行動するためには、その答えが信用できなければなりません。これは、会話型アナリティクスのロードマップを構築する上で、非常に重要な要素と言えます。
これが、Compose SDKに組み込まれた生成AI機能が、セマンティックレイヤーであるSisenseデータモデルの上に作成される理由です。これにより、アナリティクスチームは、データが適切なクエリのために最適に設計され、アナリティクスの回答からインコンテキストナラティブに移行できるようになります。Sisenseのデータモデルには、フィールド、メトリクス、数式、リレーションシップが含まれ、行と列レベルの集中セキュリティによって管理されます。
アナリティクスのための生成AI:変化に合わせてロードマップを作成する
今からOpenAIを始める場合でも、将来的に大規模言語モデルを社内に持ち込む場合でも、LLaMa 2へのギア切り替えを検討している場合でも、新しい大規模言語モデルが出現したときでも、プラグアンドプレイできることが重要です。
Sisenseがクラウドとデータベースにとらわれないのと同じように、AWS、Azure、またはGCP上でSisenseを実行したい場合でも、RedShift、Google BigQuery、または分析用の別のデータベースを使用したい場合でも、Compose SDKの生成AI機能も大規模言語モデルに柔軟に対応できるように設計しています
データベースから大規模言語モデルまで、完全なるバックエンドとアーキテクチャの柔軟性を享受しながら、最高の生成AIを使った分析体験を提供できるようにすることを目指しています。
この投稿に記載されているすべてのデータは情報提供のみを目的としており、正確ではありません。前もってご了承ください。
本記事は、Sisense社の許諾のもと弊社独自で記事化しました。
https://www.sisense.com/blog/add-gen-ai-powered-analytics-to-apps/
※ SisenseおよびSisense Hunchは、Sisense Inc の商標または登録商標です。
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
月別記事一覧
- 2026年6月 (1)
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)