
本記事は、「note.com」を使って、弊社先端技術開発グループが運営する「AIグループ@グランバレイ」で、2021年1月に掲載された記事を元に一部修正を加え、再掲載したものです。
今回は「AWS Elasticsearch Serviceを使ったElasticsearch超入門 セットアップ編」の続きとして、AWS Elasticsearch Serviceへのデータの登録とデータの検索をして行ってみます。
実際に登録していく流れに沿ってその都度説明していきます。Elasticsearchにデータを登録するイメージが伝われば幸いです!
データの作成
前回記事の作業でElasticsearchを使える環境ができたわけなので、データを登録してみます。github上に百人一首のCSVが上がっているのをこれを利用します。
csvをjsonにするのに便利なツールをご紹介します。
Node.jsが入っていれば、csvをjsonするためのツール「csvtojson」を使ってください。npxを使えば、インストールせずに使えます。ogura.csvというcsvファイルをogura.jsonに変換するには以下のコマンドを実行します。
npx csvtojson ./ogura.csv > ./ogura.json
これでjson形式にはなるのですが、今回は後々Elasticsearchにデータを一括登録(bulk登録)するため、jsonの各レコードの間に「{ “index” : {}}」という行を入れておきます。一括登録する際はこの一行が必要です。テキストエディタの置換を使ってこの行を追加し、以下のようなデータになりました。列名は適宜変えてあります。
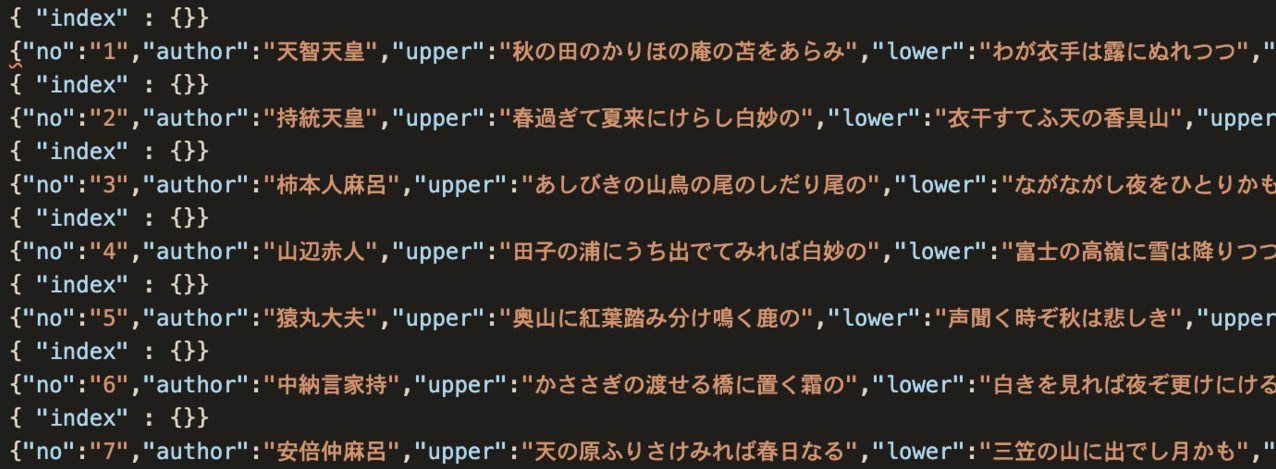
データ登録の流れ
それでは、このデータを登録していきましょう。まずはインデックスを作成します。インデックスはRDBで言う所のテーブルです。RDBであればcreate文でテーブル作成&カラム定義を行い、その後データを登録しますが、Elasticsearchだとインデックスを作成し、そのインデックスのマッピング(=カラム定義的なもの)を作成、その後にデータ登録という流れになります。以下でも①インデックスの作成、②マッピングの設定、③データの登録、という順で説明します。
また、ElasticsearchはREST APIに対応しており、HTTPリクエストを送ることでデータの登録や取得ができます。ここではcurlコマンドを使ってElasticsearchにコマンドを送っていきたいと思います。(curlコマンドはLinuxやMacではデフォルトで入っていたりaptやyum、brewで簡単にインストールできますが、Windowsだとすんなり使えなかったりするので、コチラなどを参考にしてください)
コマンドには前回作成したElasticsearch Serviceのエンドポイントが必要なので、マネージメントコンソールから確認してください。エンドポイントというのはElasticsearch ServiceにアクセスするためのURLです。
インデックスの作成
インデックス作成は以下のコマンドです。PUTリクエストなので-XPUTを指定し、-uオプションで先ほど設定したユーザー名とパスワードを指定します。「ドメインURL/つけたいインデックス名」を引数に渡せば、その名前でインデックスができます。今回はoguraというインデックスを作成しています。(『小倉百人一首』のoguraです)
curl -XPUT -u ユーザー名:パスワード
https://ドメイン.amazonaws.com/ogura
-H "Content-Type: application/json"
マッピングの設定
作成したインデックスにmappingsの設定を行います。RDBで言うところのカラム定義ですね。同じくPUTリクエストですが、引数のところでインデックス名に続けて「/_mapping」と書きます。ElasticsearchではこのようにURLの最後に指示内容をつけます。これは「エンドポイントURL」と呼ばれるようです。
mappingの内容はコマンドで書いても良いですが、jsonファイルをアップロードすることもできます。curlコマンドではファイルをアップロードする際、@マークを最初につける必要があります。
curl -XPUT -u ユーザー名:パスワード
https://ドメイン.amazonaws.com/ogura/_mapping
-H "Content-Type: application/json" -d "@パス/ogura_index.json"
ここではmappingsの定義内容としてjsonファイルをアップロードしています。mappingは以下のような内容です。json形式のファイルでpropertiesという要素の中に、各フィールドの名称とタイプを入れていきます。タイプは文字列ならtext、数値ならlongとする場合が多いと思います。また、textのanalyzerにkuromojiというものを指定していますが、こちらについては本記事末尾で補足として説明しています。
{
"properties":{
"no":{
"type": "long"
},
"author":{
"type": "text"
},
"upper":{
"type": "text",
"analyzer": "kuromoji"
},
"lower":{
"type": "text",
"analyzer": "kuromoji"
},
"upper_kana":{
"type": "text",
"analyzer": "kuromoji"
},
"lower_kana":{
"type": "text",
"analyzer": "kuromoji"
}
}
}
データの登録
「インデックスの作成とマッピング設定」ができたので、ここに先ほど準備した百人一首のデータを登録していきます。先ほど用意したjsonファイルをbulkで登録するので、パラメータで「ドメインURL/インデックス名/_bulk」を渡します。登録するjsonファイルは「–data-binary」のオプションで指定してください。
curl -XPUT -u ユーザー名:パスワード https://ドメイン.amazonaws.com/ogura/_bulk
-H "Content-Type: application/json"
--data-binary "@パス/ogura.json"
ちなみにもしbulkでなく登録するのであれば、”_bulk”の部分を”_doc”に変え、1レコード分のデータを渡します。”_doc”というと変な感じがしますが、これはElasticsearchではレコードのことを実際にはドキュメントと呼ぶためです。
データの確認
実際に登録できたか、_searchで確かめてみましょう。-dオプションで引数にjson形式のクエリを渡しています。SQLを使うとRDBから自由にデータが取り出せるように、ここのクエリの内容を変えることで様々な方法でデータが取得できます。ここではmatch_allということで、特に条件はつけずにデータを取得しています。エンドポイントURLに続けて”?pretty”と記入するとresponseが見やすい状態で返ってきます。
curl -XGET -u ユーザー名:パスワード ドメイン/ogura/_search?pretty
-H "Content-Type: application/json"
-d '{"query": {"match_all": {}}}'
返ってきた結果の冒頭部分は以下となっております。
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 100,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "HPeW6HUBZNS1GD1LaJp6",
"_score" : 1.0,
"_source" : {
"no" : "3",
"author" : "柿本人麻呂",
"upper" : "あしびきの山鳥の尾のしだり尾の",
"lower" : "ながながし夜をひとりかも寝む",
"upper_kana" : "あしびきのやまどりのをのしだりをの",
"lower_kana" : "ながながしよをひとりかもねむ"
}
},
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "KPeW6HUBZNS1GD1LaJp6",
"_score" : 1.0,
"_source" : {
"no" : "15",
"author" : "光孝天皇",
"upper" : "君がため春の野に出でて若菜摘む",
"lower" : "わが衣手に雪は降りつつ",
"upper_kana" : "きみがためはるののにいでてわかなつむ",
"lower_kana" : "わがころもでにゆきはふりつつ"
}
},
...[以下省略]
ちゃんと百人一首の歌が返ってきました。登録できてますね。hitsのtotalが100になっているので、100件のデータ(百首)が取得できたことがわかります。実際のデータはhitsの中のhitsの中に配列形式で入っています。
検索をする(matchクエリ)
それでは百人一首の歌を検索してみましょう。検索をする際はエンドポイントは先ほどと同じ_searchで、基本的なキーワード検索の際はmatchというクエリを使います。なんとなくたくさんヒットしそうな”月”という語で、上の句にクエリをかけてみます。(no(歌番号)でソートもかけています。)
curl -XGET -u ユーザー名:パスワード
https://ドメイン.amazonaws.com/ogura/_search?pretty
-H "Content-Type: application/json"
-d '{"query": {"match": {"upper": "月"}}, "sort": "no"}'
そうすると、3件のデータが返ってきました。(二首目以降省略)
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "gDrNf3YBpbvDgfLjoE6R",
"_score" : null,
"_source" : {
"no" : "23",
"author" : "大江千里",
"upper" : "月見れば千々にものこそ悲しけれ",
"lower" : "わが身ひとつの秋にはあらねど",
"upper_kana" : "つきみればちぢにものこそかなしけれ",
"lower_kana" : "わがみひとつのあきにはあらねど"
},
"sort" : [
23
]
},
...[以下省略]
「月見れば千々にものこそ悲しけれ」と上の句に”月”が含まれている歌が返ってきました。
boolクエリ
次に上の句か下の句のどちらか(もしくは両方)に”月”が含まれる歌を調べてみましょう。条件を組み合わせて「上の句に”月”が含まれる」か「下の句に”月”が含まれる」のどちらかに一致するものを抽出します。
それにはboolクエリというものを使います。boolクエリにはいくつか種類がありますが、基本となるのはAND条件の”must”とOR条件の”should”です。構文は以下のようにboolの下にmustやshouldの要素を追加し、その中に配列で個々の条件を入れていきます。
{
"query": {
"bool": {
"must": [{<クエリ>}, {<クエリ>}],
"should" [{<クエリ>}, {<クエリ>}]
}
}
}
今回は「上の句か下の句のどちらかに含まれる」というOR条件なので”should”を使います。そうすると、以下のようなコマンドになります。
curl -XGET -u ユーザー名:パスワード
https://ドメイン.amazonaws.com/ogura/_search?pretty
-H "Content-Type: application/json"
-d '{
"query": {
"bool": {
"should": [
{"match": {"upper": "月"}},
{"match": {"lower": "月"}}
]
}
},
"sort": "no"
}'
上の句を検索対象とした時に取得できたのは3首のみでしたが、今回は5首取得できました。
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 11,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "cDrNf3YBpbvDgfLjoE6R",
"_score" : null,
"_source" : {
"no" : "7",
"author" : "安倍仲麻呂",
"upper" : "天の原ふりさけみれば春日なる",
"lower" : "三笠の山に出でし月かも",
"upper_kana" : "あまのはらふりさけみればかすがなる",
"lower_kana" : "みかさのやまにいでしつきかも"
},
"sort" : [
7
]
},
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "fjrNf3YBpbvDgfLjoE6R",
"_score" : null,
"_source" : {
"no" : "21",
"author" : "素性法師",
"upper" : "今来むといひしばかりに長月の",
"lower" : "有明の月を待ち出でつるかな",
"upper_kana" : "いまこむといひしばかりにながつきの",
"lower_kana" : "ありあけのつきをまちいでつるかな"
},
"sort" : [
21
]
},
{
"_index" : "ogura",
"_type" : "_doc",
"_id" : "gDrNf3YBpbvDgfLjoE6R",
"_score" : null,
"_source" : {
"no" : "23",
"author" : "大江千里",
"upper" : "月見れば千々にものこそ悲しけれ",
"lower" : "わが身ひとつの秋にはあらねど",
"upper_kana" : "つきみればちぢにものこそかなしけれ",
"lower_kana" : "わがみひとつのあきにはあらねど"
},
"sort" : [
23
]
},
...[以下省略]
これで上の句か下の句に”月”という語が含まれる歌が検索できました。何だか切ない歌が多いですね。
Elasticsearchのクエリにはmatchの他にもmatch_queryやtermなど様々なものがあり、用途によって使い分ける必要があります。実際に使う際にはどのようなクエリを使うか調べると良いと思います。そして、bool条件を使うことでそれらを組み合わせることができます。
最後に
今回は前回作成したElasticsearch Serviceの環境でインデックスを作成し、データの登録と検索をしてみました。curlコマンドのオプションで色々な値を渡していけばいいので、SQLを覚える必要はありません。その点は意外に簡単だと感じております。
前回と今回でElasticsearchで検索を行う一番簡単な方法を紹介してきました。とりあえず検索を行うだけであれば、Elasticsearchというのは決して難しいものではないということがお伝えできたのではないかと思います。また、AWS Elasticseach Serviceを使うと、可視化ツールのKibanaもデフォルトで使える状態なのでそちらについても今後書けたらと思っております。
【補足】kuromojiについて
「マッピングの設定」の箇所で出てきたkuromojiについて簡単に補足します。
Elasticsearchでは、受け取ったテキストを一旦解析してからデータを保存することで、実際に検索する際に高速で検索結果を返します。この時の解析方法を指定するのがanalyzerで、kuromojiというのは日本語用analyzerの代表的なものです。これは通常であれば自分でインストールするものですが、AWS Elasticsearch Serviceを使うと、kuromojiも予めインストールされているので、mappingの際に指定すれば使うことができます。
特定のanalyzerを使った時にどのように文章が解析されるか、というのは_analyzeというエンドポイントURLを使うことで知ることができます。通常のstandard analyzerを使って、「世の中は常にもがもな渚漕ぐ」という源実朝の歌の上の句でanalyzerの動作確認をしてみます。
curl -XPOST -u ユーザー名:パスワード https://ドメイン.amazonaws.com/_analyze?pretty ¥
-H "Content-Type: application/json" ¥
-d '{"analyzer": "standard", "text": "世の中は常にもがもな渚漕ぐ"}'
返ってくるのがこちらです。「世」「の」「中」「は」という具合で一文字づつ分割されています。
{
"tokens" : [
{
"token" : "世",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "の",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "",
"position" : 2
},
{
"token" : "は",
"start_offset" : 3,
"end_offset" : 4,
"type" : "",
"position" : 3
},
...[以下省略]
先ほどのコマンドの「”analyzer”: “standard”」の部分を「”analyzer”: “kuromoji”」として実行すると、下記のレスポンスが返ってきます。
{
"tokens" : [
{
"token" : "世の中",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "常に",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 2
},
{
"token" : "渚",
"start_offset" : 10,
"end_offset" : 11,
"type" : "word",
"position" : 7
},
{
"token" : "漕ぐ",
"start_offset" : 11,
"end_offset" : 13,
"type" : "word",
"position" : 8
}
]
}
先ほどは一文字ずつ分割されていたのに比べ、「世の中」「常に」「漕ぐ」に文節ごとに区切られています。「もがも」(=であったらなあ)は完全に古語なので無視されていていますが、こちらは詮なきことですね。「世の中は」の「は」も無視されています。
また、analyzerは単語のフィルターや(分かち書きをする)tokenizerなどが組み合わされたものです。デフォルトのkuromoji analyzerには含まれていないフィルターも色々あるので、それらを組み合わせてオリジナルのanalyzerを作って使用することもできます。

本記事は、弊社先端技術開発グループが運営している「note」内の「AIグループ@グランバレイ」の記事を一部修正を加え転載しております。
https://note.com/gvaiblog/n/nae25d2f527e2
※ アマゾン ウェブ サービス、Amazon Web Services、AWSは、Amazon.com, Inc.またはその関連会社の商標です。
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
-
 経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
月別記事一覧
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)
- 2025年6月 (1)