
はじめに
Hadoop(ハドゥープ)は、データを複数のサーバーに分散並列をし、同時処理をするオープンソースのミドルウェア(ソフトウェア基盤)です。大量データを効率的に処理し、管理する目的で開発され、テラバイト、ペタバイト級大容量データの分析などを高速処理できるため、「ビッグデータ」活用における主要技術として導入が進んでいます。
今回、この分散処理ミドルウェアである「Hadoop 3.3ライン」においてのインストール手順についてまとめました。
導入環境
- ・Centos7(64bit)
- ・rpm 4.14.2
- ・JDK 14.0.1
- ・Hadoop 3.3.0
Hadoopとは
インストール手順の前に、まずはHadoopとは何かを改めて説明いたします。
Hadoopとは、大規模データの分散処理を支えるJavaソフトウェアフレームワークです。
大まかに言うと、
・データを分散させるための「HDFS」
・分散させたデータを効率よく処理するための「MapReduce」
という2つの機能が組み合わされたものです。
主な特徴としては、
・データ入力時のスキーマ定義が不要
・非構造化データ(画像データなど)も扱うことができる
・サーバを追加することで容量および処理性能を向上させることができる
・サーバの故障や通信障害等をシステムが検出しリカバリすることができる
などが挙げられます。
しかしながら、Hadoopにも欠点があります。
同じ処理を複数回行ったり、同じデータに何度もアクセスする場合において、その都度ストレージへのアクセスを行います。その結果、処理速度が遅いため、リアルタイム処理には向いていません。
そのため、現状では頻繁にアクセスが発生しない大量データの処理に使用されています。
JDK(Java SE Development Kit)のインストール
Hadoopのインストールは?と思われた方もいるかもしれません。
前項でHadoopはJavaソフトウェアフレームワークであると書きました。Hadoop自身はJavaで作られています。
そのため、Hadoopを操作するにはJavaの環境が必要となります。
公式HP内のwikiサイトに、「Now Apache Hadoop community is using OpenJDK for the build/test/release environment, and that’s why OpenJDK should be supported in the community. (訳:現在、Apache Hadoopコミュニティでは、ビルド/テスト/リリース環境にOpenJDKを使用しており、そのため、OpenJDKはコミュニティでサポートされる必要があります)」との記載があるので、今回はOpenJDKを最初にインストールします。
また、同サイトによるとHadoop3.3以降はJava8およびJava11をサポートしています。
そのため、インストール時にはどのJavaのバージョンがサーバーに入っているかを確認する必要がありますのでご注意ください。
※既にインストール済みの方は「Hadoopのインストール」へGO
OpenJDKをインストール
OpenJDKはyumでインストールすることができます。
> yum install java-1.8.0-openjdk
> yum install java-1.8.0-openjdk-devel
インストール後はjavaコマンドでバージョンを表示して、きちんと利用できるか確認します
> java -version
インストール先の確認
Hadoopのインストール時にインストールしたOpenJDKの保存先を設定する必要があるので、確認をしてください。
私の環境では【/usr/lib/jvm/java-1.8.0-openjdk】でした。
Hadoopのインストール
Javaの環境が用意できましたので、引き続き、Hadoopのインストールを行っていきます。
Hadoopインストール用のファイルをダウンロード
まずはApache HadoopプロジェクトサイトからHadoopをダウンロードします。
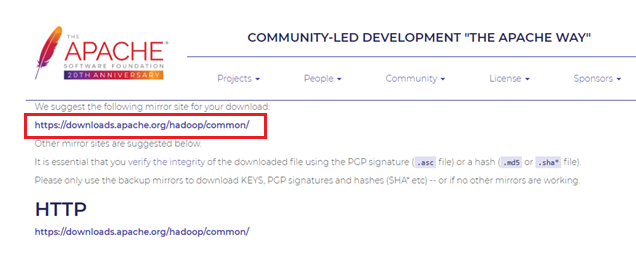
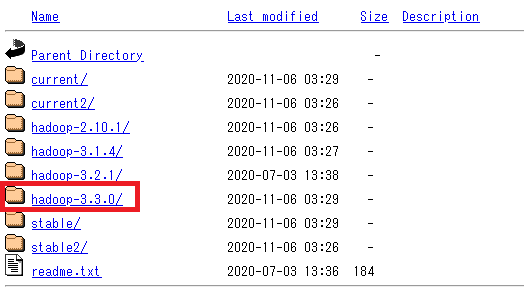
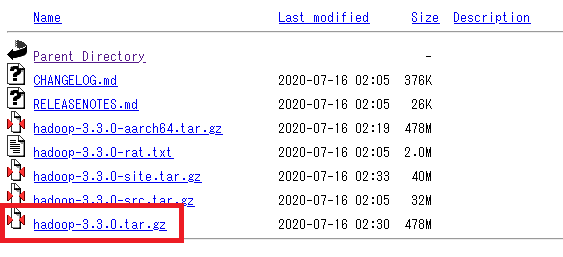
ダウンロードするファイルは【hadoop-3.3.0.tar.gz】です。
以下のコマンドでファイルをダウンロードします。
> wget https://ftp.kddi-research.jp/infosystems/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
ダウンロードしたファイルの解凍
JDKインストール時と同様に、ターミナルからスーパーユーザーでログインし、ファイルを操作します。
操作するのは【hadoop-3.3.0.tar.gz】です。
Hadoopのインストール用ファイルは圧縮されているのでまずは解凍します。
> tar zxvf hadoop-3.3.0.tar.gz
解凍すると、圧縮ファイルと同じ場所に【hadoop-3.3.0】というディレクトリが作成されるので、このディレクトリごと扱いやすい場所へ移動させておきます。
※今回は【/usr/local】へ移動させました。
ダウンロードしたファイルの解凍
続いてPATHを設定していきます。
Hadoopを使用するためには、HadoopとJavaの2種類のPATHを設定する必要があります。
設定のため、root配下の【.bashrc】を編集します。
> vi ~/.bashrc
以下の情報を【.bashrc】の末尾に追加します。
JAVA_HOME=/usr/java/jdk-14.0.1
HADOOP_INSTALL=/usr/local/hadoop-3.3.0
PATH=$HADOOP_INSTALL/bin:$JAVA_HOME/bin:$PATH
変更を保存したら、コマンドを実行して変更を反映させます。
> source ~/.bashrc
インストールの確認
最後に、きちんとインストールされているかコマンドを実行して確認します。
> hadoop version
バージョンが表示されたなら、インストール完了です!
Hadoopはインストール時点ではスタンドアロンモードとなり、ローカルファイルの操作ができます。
いろいろ操作を試してみるのも面白いので、是非ともご自身で行ってみてください。
本記事は、弊社先端技術開発グループが運営している「note」内の「AIグループ@グランバレイ」の記事を一部修正を加え転載しております。
https://note.com/gvaiblog/n/nd4df9ec910c6
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
-
 経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
月別記事一覧
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)
- 2025年6月 (1)