
本記事は、「note.com」を使って、弊社先端技術開発グループが運営する「AIグループ@グランバレイ」で、2020年7月に掲載された記事を元に一部修正を加え、再掲載したものです。
はじめに
最近、低水準言語に興味があり Python で四則演算の式をコンパイル※1するプログラムを作成してみました。今回、そのプログラムコードの流れなどを解説をしてみます。
なお、本タイトルの低レベルというのは低水準言語のことを指し、今回はアセンブリ※2を使用します。
※1. コンパイル
通常はプログラミング言語で書かれたソースコードを、機械語※3や低水準言語のプログラムに変換することを指します。今回はプログラミング言語のソースコードではなく、単純な四則演算の式(例:1+2*3)をアセンブリに変換しています
※2. アセンブリ
機械語に近い低水準プログラミング言語。機械語の命令に1対1で対応しています。アセンブリには intel 記法と AT&T 記法の2種類の記法がありますが、今回は intel 記法を使っています
※3. 機械語
機械語はマシン語とも呼ばれ、コンピュータが直接理解できる0と1のみで表現されたもの
プログラムコードの流れ
実行環境は以下の通りです。
大まかなコードの流れはこのような感じです。
- 式の読み込み
- 字句解析
- 構文木作成
- アセンブリ作成
- 実行ファイル作成
- 実行ファイル実行
本プログラムは四則演算の式を記述したファイルをプログラムに渡すと、その演算した結果が表示されるというものです。
$ echo "1+2*3-4" > expr.txt
$ python3.8 calc.py expr.txt
Expression: 1+2*3-4
Result: 3
2~4までの字句解析、構文木作成、アセンブリ作成はコンパイラの基礎的な流れになります。
余談ですが、本ソースコードは Python の四則演算子をいっさい使わないというルールでコーディングしていますので、全く役には立ちませんが不毛な試行錯誤をしています。
それでは解説していきます。
1. 式の読み込み
式の読み込みは read_file(fname) という関数で行っています。
def read_file(fname):
expr = ''
with open(fname, 'r') as f:
for c in f.read():
if c == '\n':
break
expr = f'{expr}{c}'
return expr
2. 字句解析
字句解析とは、文字列を字句※4に分割し、それぞれの字句がどういう意味を持つのかを明らかにすることです。今回は四則演算の文字列が対象なので、数値と演算子に分割できればOKです。
今回、字句解析は tokenize(expr) という関数で行っています。
この tokenize 関数に式を渡すと、式を数値や演算子で分離します。例えば”1+2*34″という文字を渡すと以下のような戻り値を返します。
[
{ type: 数値, num: 1, op: None },
{ type: 演算子, num: None, op: '+' },
{ type: 数値, num: 2, op: None },
{ type: 演算子, num: None, op: '*' },
{ type: 数値, num: 34, op: None },
]
# ※字句はディクショナリのように見えますが、実際はクラスのオブジェクトで実装
※4. 字句
それ以上、意味的に細かく分割できない文字列のこと。例えば「100」という文字列は100という数値的な意味を持ち、これ以上分割すると「1」, 「0」, 「0」と意味を成さなくなる。そのため、この場合は「100」が字句になる。
3. 構文木作成
構文木とは、字句の関係性を木構造で表したものです。
上記の例の”1+2*34″を構文木にすると以下のようになります。
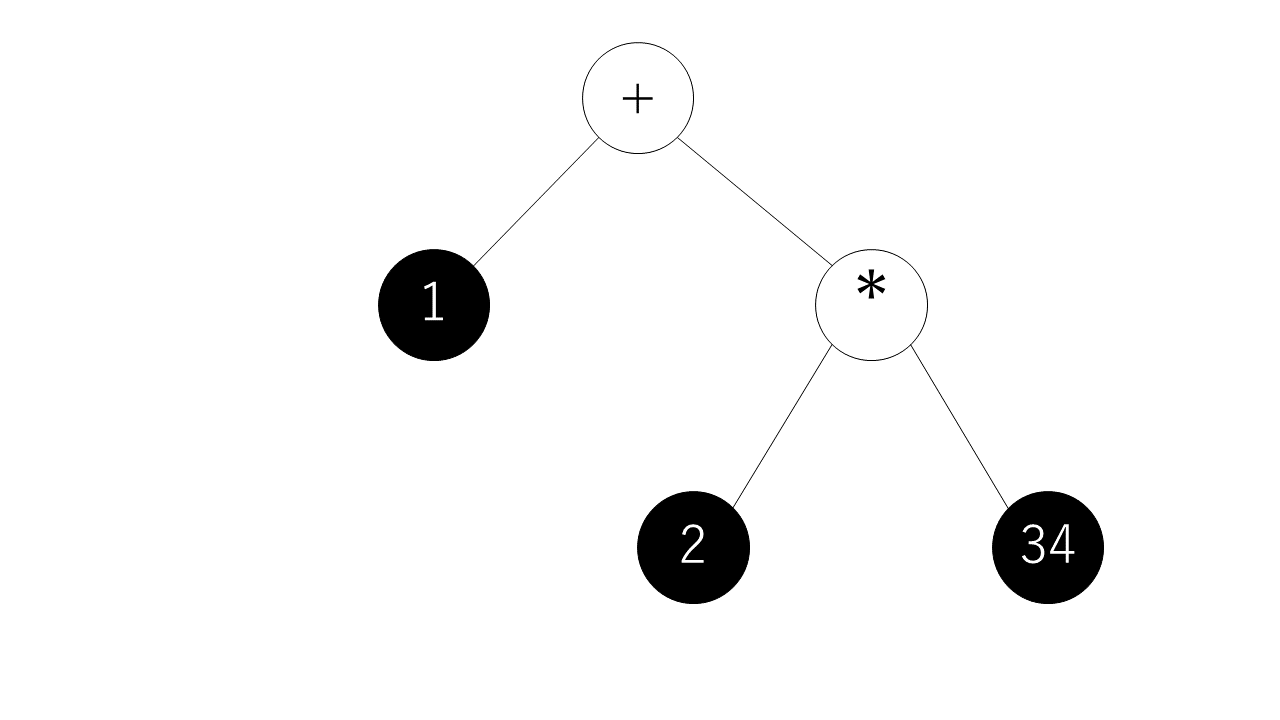
なぜ、このような構文木を作成するのかというと、演算子には優先順位があり加算減算よりも乗算除算を先に行わなければならないからです。この構文木では、”2″と”34″を”*”した結果を”1″に”+”にするということを表します。
式には括弧「( )」’を使ってさらに優先度を決めることもできますが、今回のソースコードは括弧には対応していません。
なお、構文木の作成は create_tree(tokens) という再帰関数を使っています。
4. アセンブリ作成
アセンブリ作成は、ここではあまり深く解説しませんが、数値をCPUのレジスタ※5に登録し、各演算子に対応した操作(加算:add、減算:sub、乗算:imul、除算:idiv)を行い、結果を取得するプロセスになります。
create_asm(tree, asm_name) という関数で、内部的に write_asm(node, f) という再帰関数を使って木構造をアセンブリに置き換えています。
また、演算結果はret命令でリターンコードとして返すようにしています。
※5. レジスタ
CPUに内臓されている記憶装置。CPUはこのレジスタから直接データを取り出し、演算を行い、その演算結果を再びレジスタに格納するという動作を行っている。また、演算結果の格納だけではなくメモリのアドレスも格納する
5. 実行ファイル作成
4.で作成したアセンブリファイルを assemble(asm_name, bin_name) という関数内で、gccを使用して実行ファイルに変換しています。
subprocess.run(['gcc', '-o', bin_name, asm_name])
6. 実行ファイル実行
実行ファイル実行はその名の通り、5.で作られた実行ファイルを実行するのみです。なお、演算結果は実行ファイルのリターンコードから取得できますので、リターンコードをそのまま演算結果としてprintします。
ソースコード
今回作成したコードは Github にあげています。
以下よりダウンロードしてみてください
https://github.com/Goda-Tetsuya/low-level-calculator
最後に
日々の業務ではPythonを使っていますが、低水準言語の知識も習得したいと思い、今回このようなプログラムを作成しました。実際にいろいろと試してみるとCPUやメモリの知識のみならず、プログラミングの歴史や先人の知恵に触れることができ、大変面白く感じています。(例えば今回使った字句解析や構文木なども先人が考え出したものです)
低水準言語は敷居が高いと思われていますが、身近な言語であるPythonから初めて見たらどうでしょうか。
プログラミングの知識を高める上で、お勧めします。
本記事は、弊社先端技術開発グループが運営している「note」内の「AIグループ@グランバレイ」の記事を一部修正を加え転載しております。
https://note.com/gvaiblog/n/n73d547b246d0
Photo credit: Christiaan Colen on Visualhunt
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
-
 経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
月別記事一覧
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)
- 2025年6月 (1)