
過去10年間でデータストレージの価格は劇的に下がりました。その結果、企業は大量のデータを収集することが容易になり、今まで以上に生データを扱えるようになりました。その反面、現状多くの組織は、この大量データを効果的な分析につなげることができていないのも事実です。その主な原因は、企業内に分析する洞察力を持つ社員がいないことです。大量の生データを利用するには、分析力と技術力の両方が必要ですが、そうした人材を育成するにはコストや時間がかかってしまいます。
効果的なモデル開発を行うためには研究を行うことが重要ですが、研究は時間とコストの制限に大きな影響を受けるため、ビッグデータの効果的な利活用方法を見つけることができるとは言えません。処理の待ち時間、人的資源、技術コスト、および期待される精度が絶え間なくトレードオフされており、これらの要素が、多くの企業でビッグデータから価値ある気づきを得ることができない原因となっています。
難解なビッグデータへの取り組み
分析コストを削減するための試みは「data cognition」と呼ばれています。これはデータを処理し、理解するといった人間の考える力を模倣する一連の技術です。この技術は大量のデータを解釈するためにニューラルネットワークのようにさまざまな機械学習技術が適用されています。
Sisenseは、これらの技術を活用した最先端のデータ認識エンジンSisense Hunch™の開発を行ってきました。Sisense Hunchは、大規模なデータセットに対するSQLクエリの結果を出すことにより、数MBのモデルを作成し、数TBバイトのデータから結果を取得するディープニューラルネット(DNN)を作成します。 Sisense Hunchの最も優れた部分は、データ量が増えてもクエリの応答時間が変わらないため、非常に大きなデータセットに対しても正確で迅速なクエリを実行できることです。これにより、ビッグデータを分析する際に、インフラストラクチャや専門的なスキルの獲得に多額な投資を行う必要がなくなります。
Sisense Hunchを際立たせる特徴
Sisense Hunchが他のクエリ近似手法と違ってどのようなメリットがあるかを知るには、まず既存の近似手法の限界を知ることが重要です。
具体的には、近似手法は大容量のデータには対応できず、数種類の分析のみをサポートし、データセット全体に対して絶えずアクセスする必要があります。
近似手法に対する最初のアプローチは、データセット全体の特性をマッピングするために複数のデータサンプルを取得することでした。ただしその方法では、データセットが大きくなるにつれて、サンプリングにも時間がかかるため、運用に問題が発生します。たとえば、10億行の1%をサンプリングするとなると、1000万のサンプルが必要になり、それぞれが数百万行のサイズになります。
もう1つのアプローチは、膨大な量のクエリに対して前処理を行うことでしたが、新しい分析や多様な分析を実行するには柔軟性に欠けていました。他にも、データに統計モデリングを適用するツールを使用する方法がありますが、この場合、プロセスを変更するたびにデータセットにアクセスしなければなりませんでした。
Sisense Hunchは、これらの3つの課題すべてを解決します。スケーラブルでさまざまな分析行うことができ、さらにはデータセットから切り離しても機能する近似エンジンを提供します。実際、Sisense Hunchモデルは非常に軽量なので、携帯電話、IoTセンサー、さらにはエアコンなどの機器にもインストールが可能です。
Sisense Hunchの構造
Sisense Hunchはリカレントニューラルネットワーク(RNN)を使ってトレーニング、テスト、そしてデプロイを行います。RNNは、長く連なったデータを保持し「記憶」させることが可能です。これは特に、長くて複雑になる可能性があるSQLクエリの解釈とトレーニングに対して役立ちます。
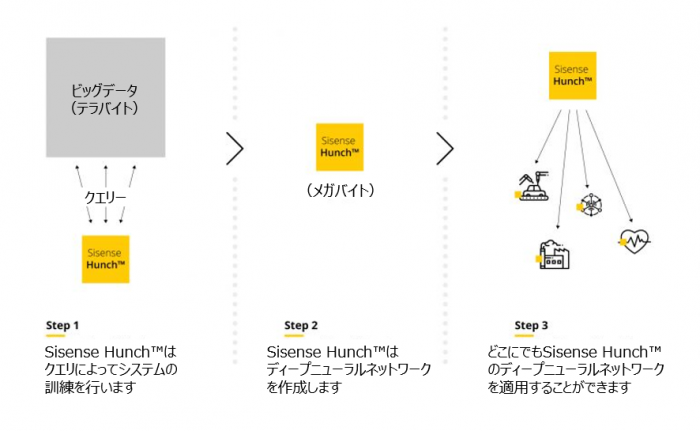
まず始めに、Sisense Hunchは、データの構造とその属性分布を理解するためにデータセット全体をスキャンします。この初期マップに基づき、正確な結果を取得するために実行される多数のSQLクエリを生成することによって、トレーニングデータセットが作成されます。これらのSQLクエリは数値行列にエンコードされ、RNNに入力されます。ここでSisense Hunchモデルは、SQLのさまざまなクエリの構造(where句、select句などに含まれるもの)とそれらの結果との関係を学習します。これにより、最小85%の精度で予測された新しいクエリが作成されます。
一度クエリが定義されれば、24時間以内にSisense Hunchモデルを構築して検証することができます。 Sisense Hunchモデルは、API経由でデプロイされアクセス可能になります。デプロイは、クラウドインフラストラクチャが使用されており、クエリを処理するのに必要な性能とスループットの結果を提供します。または、GPUを搭載したサーバーを利用してオンプレミスでインストールすることもできます。
新しいデータサンプルをAPI経由で渡して、データセット全体の一部であるかのように分析することができます。また、新しいデータをSisense Hunchに入力して、より正確なモデルを再構築するといったプロセスを、バッチとして実行することも可能となっています。
Sisense Hunchの利点と応用
Sisense Hunchには明確な利点があります。まず、Sisense Hunchモデルは元のデータセットから完全に分離することが可能です。つまり、このモデルはオフラインでもファイアウォールの内側でも維持することができ、あらゆる種類のセキュリティインフラストラクチャをサポートできます。
Sisense Hunchのモデルは実際のデータセットより1桁小さく、TBのデータモデルを数MBに圧縮します。これにより、Sisense Hunchは特に軽量になり、数多くのデバイスやセンサーに展開できます。
Sisense Hunchモデルが分離され圧縮されているということは、既存のデータセットを参照したり、新しい値の精度を比較したりするためにSisense Hunchモデルにすばやくアクセスできることを意味します。そしてこれは、複雑なSQLや未学習の分析であっても、精度を大幅に損なうことなくサポートされます。 Sisense Hunchは、集計、where、group-by句など、SQLを幅広くサポートしており、より複雑なSQLクエリが実行できるように拡張を行っています。
これらの要因により、Sisense Hunchはデータが増大しても、分離され圧縮されているため移植性があるスケーラブルな仕組みとなっています。さらに、分析クエリの変更をその場で行えるため、迅速に開発が可能です。この機能の組み合わせは、製造、セキュリティ、金融、医療、広範なモデル開発などの多くのユースケースに適しています。
ユースケースの一つとして、製造工場にリアルタイム分析を提供する「リアルタイムエッジ分析」というものがあります。たとえば、製造ラインの機械にSisense Hunchモデルを使用することで、製造プロセスを継続するか停止するか、または人間の専門家を巻き込むかについて、瞬時に決定を下すことができます。この自律性によって、機械の欠陥が劇的に減少し、生産性を向上させます。
別の例として、Sisense Hunchを使ってあらゆるデータの発見や探索プロセスを行い、特徴抽出とモデル構築のプロセスをスピードアップすることができます。たとえば、データアナリストが解約に関する仮説を持っている場合、Sisense Hunchを使用してさまざまなセグメントに対して数千のクエリを実行し、その結果を使用して仮説を検証することができるようになります。
この投稿に記載されているすべてのデータは情報提供のみを目的としており、正確ではありません。前もってご了承ください。
本記事は、Sisense社の許諾のもと弊社独自で記事化しました。
https://www.sisense.com/blog/the-architecture-of-mastering-big-data-with-sisense-hunch/
※ SisenseおよびSisense Hunchは、Sisense Inc の商標または登録商標です。
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 AIエージェントの開発入門
AIエージェントの開発入門
-
 「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
月別記事一覧
- 2026年7月 (1)
- 2026年6月 (1)
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)