
本記事は、弊社AIコンサルティンググループが運営している「note」の「AIグループ@グランバレイ」にて、2019年10月に掲載した記事を元に一部修正を加え再掲載いたしました。
データ分析も機械学習を進める上で、絶対必要なのが、データソースです。ERPやCRMなどDBを利用するアプリケーションからは正規化され分析しやすいデータを利用することは可能ですが、時には、それ以外のデータを利用し、分析や機械学習をしたいことが出てくることがあります。
Webサイトで使われる画像を集め機械学習の学習データづくりや、SNSのクチコミを集計するためのデータソースづくりに、実はプログラミングによって自動的に情報を抽出し収集することが可能です。
今回は自社でも利用する開発言語 Pythonを利用して「Webサイトから情報を抽出し収集する方法」をご紹介いたします。
Webスクレイピングとは
プログラムの内容へ進む前に、Webスクレイピングって何?という方へ簡単にご説明します。
Webスクレイピングとは、Webページの情報を抽出・収集することを指します。プログラミング言語と組み合わせれば、複数のWebページからデータを自動で抽出できたりもします。とても便利そうですね。
ただし、使用時には“抽出データの利用目的が法に抵触しないか”や“対象のWebサイトがWebスクレイピングを許可しているか”などを事前に確認する必要がありますので、利用する場合は必ず利用規約などでご確認することお勧めします。
Webスクレイピングのソースコード
では、さっそく本編へ。
今回は、弊社グランバレイのホームページ(https://www.granvalley.co.jp/)をターゲットにしてWebスクレイピングを行っていきます。
ホーム画面です。
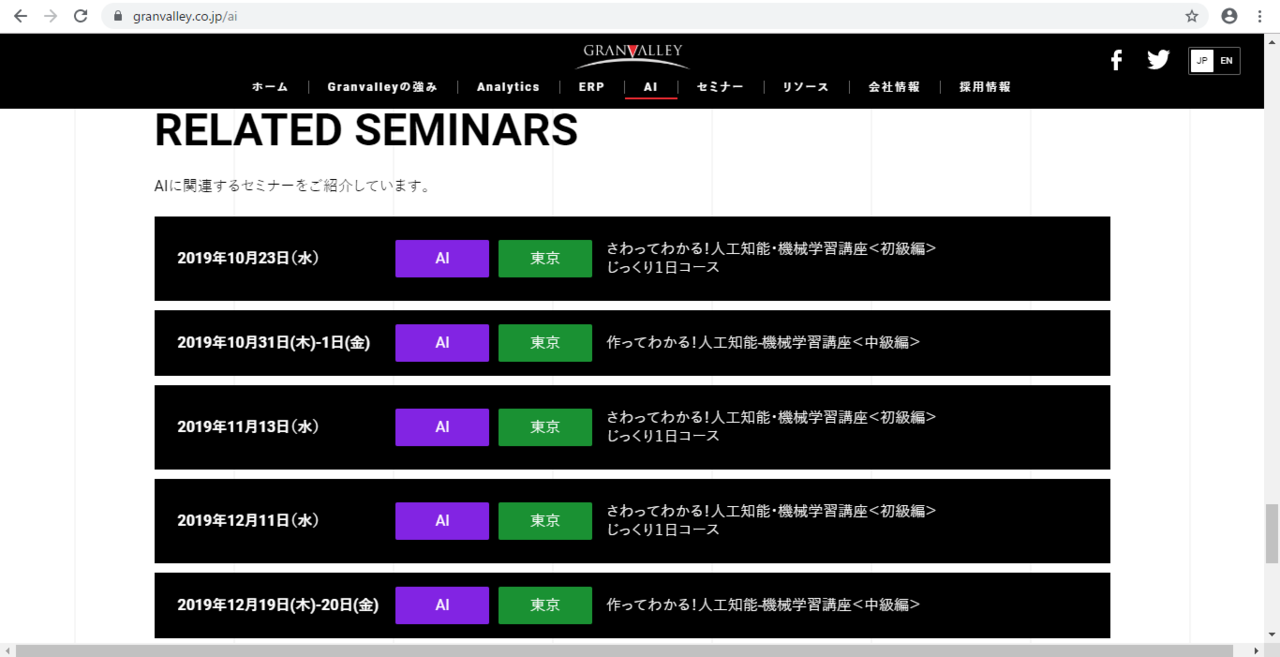
AIサービスのページの中にあるセミナー情報をWebスクレイピングしてみます。
このページのセミナー情報は、グランバレイで定期的に開催している機械学習セミナーの一覧表で、今回は、このセミナー一覧からセミナー情報を抽出しCSVファイルへ出力してみます。
完成したプログラムはこちらです。
ソースコード
## 必要なライブラリのインポート ————–
# データ加工
import pandas as pd
import numpy as np
# スクレイピング
from bs4 import BeautifulSoup
import requests
# ログ抽出
import logging.config
logging.config.fileConfig(‘./logging.conf’)
logger = logging.getLogger()
import traceback
# 変数セット ——————————
URL = ‘https://www.granvalley.co.jp/ai’
csvpath = ‘./seminarsinfo.csv’
# スクレイピング —————————
try:
# URLを開く
response = requests.get(URL)
# HTMLを取得
soup = BeautifulSoup(response.content, ‘html.parser’)
logger.info(‘Webサイトと接続できました’)
except:
tb = traceback.format_exc()
logger.error(tb)
logger.info(‘Webサイトとの接続が確立できませんでした’)
# HTML上の任意の箇所を抽出
soup = soup.find_all(‘span’,[‘date’,’cat’,’place’,’ttl’])
# テキストのみをリストで取得
soup_list = [x.text for x in soup]
# 成形のため配列に格納
soup_array = np.array(soup_list)
# 2次元配列に変換
shape_w = 4
shape_h = soup_array.size / shape_w
soup_array = soup_array.reshape(shape_h, shape_w)
# DFに変換
seminarsinfo = pd.DataFrame(soup_array)
# カラム名を指定
seminarsinfo = seminarsinfo.rename(columns={0:’日付’,1:’カテゴリ’,2:’開催地’,3:’タイトル’})
# csv出力 ——————————-
try:
seminarsinfo.to_csv(csvpath, index=False)
logger.info(‘seminarsinfo.csvの書き込みが完了しました’)
except:
tb = traceback.format_exc()
logger.error(tb)
logger.info(‘seminarsinfo.csvの書き込みに失敗しました’)
出力結果
日付,カテゴリ,開催地,タイトル
2019年10月31日(木)-1日(金),AI,東京,作ってわかる!人工知能-機械学習講座<中級編>
2019年11月13日(水),AI,東京,さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2019年12月11日(水),AI,東京,さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2019年12月19日(木)-20日(金),AI,東京,作ってわかる!人工知能-機械学習講座<中級編>
実行環境
・開発言語・・・・ Python 3.5.2
・ライブラリ・・・ BeautifulSoup4 4.5.1 / requests 2.13.0 / NumPy 1.14.2 /
Pandas 0.20.3
※今回使用しているBeautifulSoup4、requests、NumPy、Pandasは外部ライブラリなので別途インストールが必要です。
ログ出力プログラム「logging.conf」について
今回は短いプログラムなのでログを取る必要はあまりありませんが、勉強のため取得しています。不要であれば記述を削ってしまっても大丈夫です。
もしログを取得する場合は、実行するpyファイルと同じフォルダに、以下のソースプログラムを記載したファイル名「logging.conf」を作成し、logという名前の空ファイルを置けば、ログファイル(scraping.log)が作成されます。
コード内でloggerモジュールをインポートすることもお忘れなく!
[loggers]
keys=root
handlers=fileHandler [handler_fileHandler] class=FileHandler
formatter=simpleFormatter
args=(‘./log/scraping.log’,’a’) [formatter_simpleFormatter] format=[%(asctime)s][%(levelname)s](%(filename)s:%(lineno)s) %(message)s
datefmt=%Y/%m/%d %H:%M:%S
Webスクレイピングコードの解説
この項では、どのような意図でコードを書いているのかという部分を説明していこうと思っていますので、ライブラリなどについての詳細にはあまり触れません。
気になる方は、この項の最後に関連するリンクを掲載していますのでそちらをご覧ください。
それでは、まずはこの記述から。
response = requests.get(URL)
soup = BeautifulSoup(response.content, ‘html.parser’)
スクレイピングをするために必須の記述です。
URLを開き、WebページのHTMLやXMLをBeautifulSoup4の形式で変数に格納しています。
これによってPythonでWebページの情報が取得できるようになります。
ちなみに、soupの中身はこんな感じ。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<meta content="width=device-width,initial-scale=1" name="viewport"/>
<link href="https://www.granvalley.co.jp/wp/wp-content/themes/granvalley/img/favicon.ico" rel="icon" type="image/vnd.microsoft.icon"/>
<meta content="グランバレイは、これらの課題に対して、クラウド上のデータを活用し、AI-人工知能-や機械学習、データ分析を通じて「ビジネスモデル創出」の支援や「業務の効率化/スリム化」を実現するサービスやソリューションを提供します。" name="description"/>
<meta content="AI,AI,AI,ANALYTICS,Analytics,Anaplan,Anaplan,BI,BOARD,cloud,GV,IBM,Infor,IoT,Microsoft,Oracle,Others,Pentaho,Qlik,Qlik Sense,QlikView,R,SAP,SAS,Sisense,Sisense,Tableau,TIPS,WingArc1st,Yellowfin,グランバレイ,モータースポーツアナリティクス,ロボティクス,事例,名古屋,大阪,投稿をトップに表示,提供サービス,新機能,東京,製品情報,製品評価,軽技Web,BIコンサルティング,経営分析,データ分析,ソリューション,SAP,BW,Qlik,Infor BI" name="keywords"/>
<meta content="Copyright (c) 2019 GRANVALLEY Co.,Ltd." name="copyright"/>
<title>AIサービス | グランバレイ株式会社</title>
<meta content="article" property="og:type"/>
<meta content="AIサービス | グランバレイ株式会社" property="og:title"/>
<meta content="グランバレイは、これらの課題に対して、クラウド上のデータを活用し、AI-人工知能-や機械学習、データ分析を通じて「ビジネスモデル創出」の支援や「業務の効率化/スリム化」を実現するサービスやソリューションを提供します。" property="og:description"/>
<meta content="https://www.granvalley.co.jp/wp/wp-content/themes/granvalley/img/ogp.png" property="og:image"/>
<meta content="https://www.granvalley.co.jp/ai" property="og:url"/>
<meta content="グランバレイ株式会社" property="og:site_name"/>
<meta content="96348" property="fb:admins"/>
<meta content="https://www.facebook.com/granvalley/" property="article:publisher"/>
<meta content="summary_large_image" name="twitter:card"/>
<meta content="@granvalleyjapan" name="twitter:site"/><link
開いたURLのHTML(XML)をすべて取得していきますが、これでは目的の箇所がどこなのか全く分かりません。
そのため、次に目的の箇所のみを抽出します。
その記述がこちら。
soup = soup.find_all(‘span’,[‘date’,’cat’,’place’,’ttl’])
BeautifulSoup4のfind_allメソッドを使って、指定したタグおよびクラスのみを抽出しています。
対象のタグ、クラスは実際のHTML(XML)を確認してください。
今回は、spanタグのdate、cat、place、ttlというクラスを抽出しています。
ちなみに、この時のsoupの中身はこんな感じ。
# 見やすくするため改行していますが、実際は一行で出力されます。
<span class="cat" style="background-color:#8224e3;">AI</span>,
<span class="place" style="background-color:#1a9133;">東京</span>,
<span class="ttl">作ってわかる!人工知能-機械学習講座<中級編></span>,
<span class="date">2019年11月13日(水)</span>,
<span class="cat" style="background-color:#8224e3;">AI</span>,
<span class="place" style="background-color:#1a9133;">東京</span>,
<span class="ttl">さわってわかる!人工知能・機械学習講座<初級編><br/>じっくり1日コース</span>,
<span class="date">2019年12月11日(水)</span>,
<span class="cat" style="background-color:#8224e3;">AI</span>,
<span class="place" style="background-color:#1a9133;">東京</span>,
<span class="ttl">さわってわかる!人工知能・機械学習講座<初級編><br/>じっくり1日コース</span>,
<span class="date">2019年12月19日(木)-20日(金)</span>,
<span class="cat" style="background-color:#8224e3;">AI</span>,
<span class="place" style="background-color:#1a9133;">東京</span>,
<span class="ttl">作ってわかる!人工知能-機械学習講座<中級編></span>]
目的の部分だけを抽出できましたが、タグやら何やら余計なものが付帯してきます。今回必要なのはテキスト部分のみなので、次に余計な部分を削り必要な部分だけを取得します。
その記述がこちら。
soup_list = [x.text for x in soup]
soupのテキスト部分のみを抽出し、リストに格納するという処理をこの一行で行っています。
ちょっと余談ですが、このコードは内包表記という書き方で記述をしています。Pythonではメジャーな記述で、コードの行数を減らすことができるのでとても便利です。ちなみに、内包表記を使わない場合の記述はこのような感じです。
soup_list = []
for x in soup:
soup_list = np.append(x.text)
出力結果は同じですが、内包表記のほうが見た目がすっきりしますね。
それでは、説明に戻ります。
ちなみにsoup_listの中身はこんな感じです。
[‘2019年10月31日(木)-1日(金)’, ‘AI’, ‘東京’, ‘作ってわかる!人工知能-機械学習講座<中級編>’, ‘2019年11月13日(水)’, ‘AI’, ‘東京’, ‘さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース’, ‘2019年12月11日(水)’, ‘AI’, ‘東京’, ‘さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース’, ‘2019年12月19日(木)-20日(金)’, ‘AI’, ‘東京’, ‘作ってわかる!人工知能-機械学習講座<中級編>’]
テキストのみを抽出することはできましたが、一行で出力されてしまいました。
このままでは見づらいので、NumPyを使って形を整えていきます。
その記述がこちら。
soup_array = np.array(soup_list)
shape_w = 4
shape_h = soup_array.size / shape_w
soup_array = soup_array.reshape(shape_h, shape_w)
まずはNumPyで処理できるようにするため、arrayメソッドを使ってsoup_listを1次元配列に変換します。
そのあと、shape_wとshape_hを指定していますが、ここでreshapeメソッドで変換する2次元配列の大きさを決めています。
shape_hについては数式によって値を求めていますが、これはHTML(XML)を取得するタイミングで変化する値だからです。
sizeメソッドで配列の要素数を取得し、これを列数で割ることで、変換する配列の行数を求めています。
この処理で、1次元配列をshape_h行4列に変換しました。
soup_arrayの中身はこのような感じとなります。
[[‘2019年10月31日(木)-1日(金)’ ‘AI’ ‘東京’ ‘作ってわかる!人工知能-機械学習講座<中級編>’]
[‘2019年11月13日(水)’ ‘AI’ ‘東京’ ‘さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース’]
[‘2019年12月11日(水)’ ‘AI’ ‘東京’ ‘さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース’]
[‘2019年12月19日(木)-20日(金)’ ‘AI’ ‘東京’ ‘作ってわかる!人工知能-機械学習講座<中級編>’]]
各回ごとに並んで、たいぶん見やすくなりました。
もっと見やすくするために、項目名を表示させたいと思います。
項目名の表示には、Pandasのデータフレームを使います。
その記述がこちら。
seminarsinfo = pd.DataFrame(soup_array)
まず、先ほど形を整えた2次元配列soup_arrayをデータフレームに変換します。
データフレームに変換することで、自動的にインデックス名とカラム名をくっつけてくれます。
0 1 2 3
0 2019年10月31日(木)-1日(金) AI 東京 作ってわかる!人工知能-機械学習講座<中級編>
1 2019年11月13日(水) AI 東京 さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2 2019年12月11日(水) AI 東京 さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
3 2019年12月19日(木)-20日(金) AI 東京 作ってわかる!人工知能-機械学習講座<中級編>
出力結果はこのような形となります。ちなみに、行ごと付けているのがインデックス名、列ごとに付いているのがカラム名です。
ただ、自動で付けたものはただの数値のためわかりづらいので、わかりやすいように日本語にします。
その記述がこちら。
seminarsinfo = seminarsinfo.rename(columns={0:’日付’,1:’カテゴリ’,2:’開催地’,3:’タイトル’})
renameメソッドでカラム名を任意の文言に変換しています。変換したものがこちら。
日付 カテゴリ 開催地 タイトル
0 2019年10月31日(木)-1日(金) AI 東京 作ってわかる!人工知能-機械学習講座<中級編>
1 2019年11月13日(水) AI 東京 さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2 2019年12月11日(水) AI 東京 さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
3 2019年12月19日(木)-20日(金) AI 東京 作ってわかる!人工知能-機械学習講座<中級編>
列名が表示されました。
あとはCSVファイルへ出力するだけですが、データフレームに変換したときにくっついてきたインデックス名が残っています。
できれば削除したいので、to_csvメソッドを使い、インデックスの表示を変更することにします。
その記述がこちら。
seminarsinfo.to_csv(csvpath, index=False)
引数のindexにFalseを記述することで、CSVファイルへ出力するデータにはインデックス名が表示されなくなります。
出力された最終形のCSVファイルがこちらとなります。
日付,カテゴリ,開催地,タイトル
2019年10月31日(木)-1日(金),AI,東京,作ってわかる!人工知能-機械学習講座<中級編>
2019年11月13日(水),AI,東京,さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2019年12月11日(水),AI,東京,さわってわかる!人工知能・機械学習講座<初級編>じっくり1日コース
2019年12月19日(木)-20日(金),AI,東京,作ってわかる!人工知能-機械学習講座<中級編>
おわりに
取得したいWebページの仕様によっては、このプログラムを使ってもうまくいかない場合があるかもしれませんが、Webスクレイピングは大体このような流れとなります。
今回初めてWebスクレイピングに挑戦しましたが、日本語の文字化けや取得タイミングによるWebページ画面の変化などに苦戦しました・・・。
皆様も是非とも、挑戦してみてください。

本記事は、弊社AIコンサルティンググループが運営している「note」内の「AIグループ@グランバレイ」の記事を一部修正を加え転載しております。
https://note.com/gvaiblog/n/n643366dacc57
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
-
 経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
経営者の『勘』を『確信』へ。AIとの対話が生む、インサイト血肉化の全貌
月別記事一覧
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)
- 2025年6月 (1)