
本記事では、次世代のデータアーキテクチャとして注目される「データレイクハウス」について、その独自性、アーキテクチャ、そして導入におけるメリットを分かりやすく解説します。
データレイクハウスは、データレイクとデータウェアハウスの利点を融合した新たなデータ管理手法です。従来の課題を克服し、社内に散在するデータを一元化・最適化することで、ビジネスの価値を最大限に引き出します。
データレイクハウスとは?
データレイクハウスとは、データレイクが持つ低コスト・スケーラビリティ・多様なファイル形式への柔軟性と、データウェアハウスが持つ高いパフォーマンス・ガバナンス・信頼性を融合させた、最新のデータ管理アーキテクチャです。
データレイクハウスの特徴
データレイクハウスの主な特徴は以下の通りです。
・多様なデータ形式のサポート
従来のトランザクションデータ(CSV, Parquet, Avroなど)から、画像、動画、テキスト(PNG, MP4, TXTなど)に至るまで、構造化・非構造化を問わず、あらゆるデータを容易に格納し、分析できます。
・ベンダーロックインの回避
Apache Parquet、Iceberg、ORCといったオープンソースのファイル形式を採用しているため、特定のツールやベンダーに縛られることなく、自由にテクノロジーを組み合わせることが可能です。これらのフォーマットはSparkなどのコンピュートエンジンとシームレスに連携し、ビジネスアナリストからデータサイエンティストまで、多様なユーザーがSQL、Python、Scala、Rといった使い慣れた言語でデータにアクセスできます。
・データ品質の確保
スキーマ(データの構造定義)や検証ルールを適用することで、新たに追加されるデータが定義された構造に準拠していることを保証し、データの一貫性を維持します。
・データガバナンスの強化
包括的なアクセス制御、詳細なリネージ(データの系譜)追跡、豊富なメタデータ管理、そして詳細な監査証跡により、誰がどのようにデータを利用しているかを容易に可視化し、統制を強化します。
・ストレージとコンピュートの分離
ストレージ(データを保管する場所)とコンピュート(データを処理する能力)を分離しているため、それぞれの要件に応じて独立して拡張できます。これにより、柔軟性とコスト効率が大幅に向上します。
・リアルタイム分析/リアルタイムレポーティングをサポート
BIツールがデータソースに直接アクセスできるため、常に最新のデータに基づいたインサイトを得られます。分析のたびにデータの複製・移動が必要ありません。また、ストリーミングデータ(次々と発生するデータ)をリアルタイムで取り込み、データ到着と同時にインサイトを生成することも可能です。
・AI導入の促進
多様なデータと豊富なメタデータを一元管理し、CPUからAI専用アクセラレータまで動的なコンピュートリソースをサポートします。さらに、エンタープライズレベルのセキュリティ統制により、AIプロジェクトを安全かつ迅速に推進します。
・ACIDトランザクションによるデータの信頼性を確保
データベースの世界で信頼性の指標とされるACID特性(原子性、一貫性、独立性、永続性)をサポートし、データの一貫性と完全性を保証します。
1) 原子性 (Atomicity):
トランザクション内の処理は、全て実行されるか、あるいは全く実行されないかのどちらであり、部分的な実行は許容されず、途中で失敗した場合でも、処理が開始される前の状態にロールバックされます。
2) 一貫性 (Consistency):
トランザクションの実行前後で、データベースの整合性制約が維持されることが保証され、データの不整合を防ぎ、常に正しい状態を保ちます。
3) 独立性 (Isolation):
複数のトランザクションを同時に実行しても、それぞれのトランザクションは独立して実行されているかのように振る舞います。 あるトランザクションが途中の状態にある場合でも、他のトランザクションがその状態に影響を与えることはありません。
4) 永続性 (Durability):
トランザクションが正常に完了した後、その処理結果は失われることはありません。 システムに障害が発生しても、完了したトランザクションの変更はデータベースに記録され、保持されます。
データレイクハウスと従来技術の違い
データレイクハウスは、データウェアハウスとデータレイクの長所を統合し、構造や柔軟性を損なわず統一されたデータストレージを提供します。
ここでは、従来技術であるデータウェアハウスとデータレイクについて見ていきます。
データウェアハウス (DWH) とは
1980年代からデータ管理の主流であったデータウェアハウスは、様々なソースからのデータを統合し、構造化されたスキーマに整理して格納する中央集権的なリレーショナルデータベースです。主にBI(ビジネスインテリジェンス)やレポーティングに利用されます。
データウェアハウスの課題
その強力な機能にもかかわらず、データウェアハウスにはいくつかの課題も持ち合わせていました。
- 大量データ処理の高コスト
- 非構造化・半構造化データの扱いに限界
- ストリーミングデータの効率的な処理が困難
- 新規データソースの統合に時間と労力が必要
データレイクとは
データレイクは、データウェアハウスの課題を解決するため、2010年代に登場しました。オープンなファイル形式を使い、膨大な量の生データを低コストで保存するソリューションです。データウェアハウスとは異なり、データ格納時にスキーマを強制しません(スキーマオンリード)。これにより、動画、テキスト、画像、音声など、多様な形式のデータを柔軟に格納できます。この特性から、データレイクはビッグデータ、AI、機械学習の分野で広く活用されています。
データレイクの課題
その柔軟性の一方で、データレイクにも課題が存在します。
– BIで一般的なSQLクエリを実行するには追加のツールが必要
– データ品質とデータガバナンスの維持が困難
– 堅牢なセキュリティやアクセス制御機能の不足
– データが整理されず、古く使われないデータが溜まっていく「データスワンプ(データの沼)」化のリスク
データレイクハウス:両者の強みを統合
データレイクハウスは、データウェアハウスとデータレイクの利点を単一アーキテクチャに統合。従来のデータレイクからデータウェアハウスに必要なデータを抽出・加工して転送する「2層アーキテクチャ」の複雑さを解消し、シンプルで効率的なデータ管理を実現します。
データレイクハウスの価値
データレイクハウスを利用することで、以下のような明確なメリットを提供します。
・データ品質と信頼性の向上
スキーマ適用機能と一元化されたデータストレージがデータ品質を向上させます。また、組み込みのガバナンス機能により、データの来歴追跡やコンプライアンス遵守が容易になります。
・コスト効率の高いストレージ
構造化・非構造化を問わず、すべてのデータを一か所に集約することで、データサイロ(分断されたデータ)に起因する複数のストレージ管理コストを削減します。
・BIと高度な分析のサポート
オープンなファイル形式により、BIツールから機械学習、AIまで、様々な用途でデータをシームレスに利用できます。これにより、定型的なレポーティングから戦略的な洞察まで、包括的なデータ活用が可能になります。
・データ重複の削減
データを一元管理することで、目的別にデータを複製する必要性を最小限に抑え、データ管理の複雑さを軽減します。
・柔軟で統一されたデータアクセス
構造化データと非構造化データに一か所からアクセスできるため、日々のレポーティングから高度なモデリングまで、多様なワークロードに対して迅速かつ多角的な分析が可能になります。
・オープンアーキテクチャ
Apache Parquet、Iceberg、ORCといったオープンなファイル形式を採用しているため、特定のベンダーに縛られることなく、ビジネスニーズの変化や技術の進化に合わせて柔軟にツールを組み合わせることができます。
データレイクハウスのアーキテクチャ
データレイクハウスのアーキテクチャは、効率的なデータの格納、管理、アクセスを単一のシステムで実現するために設計された、複数のレイヤー(層)で構成されています。
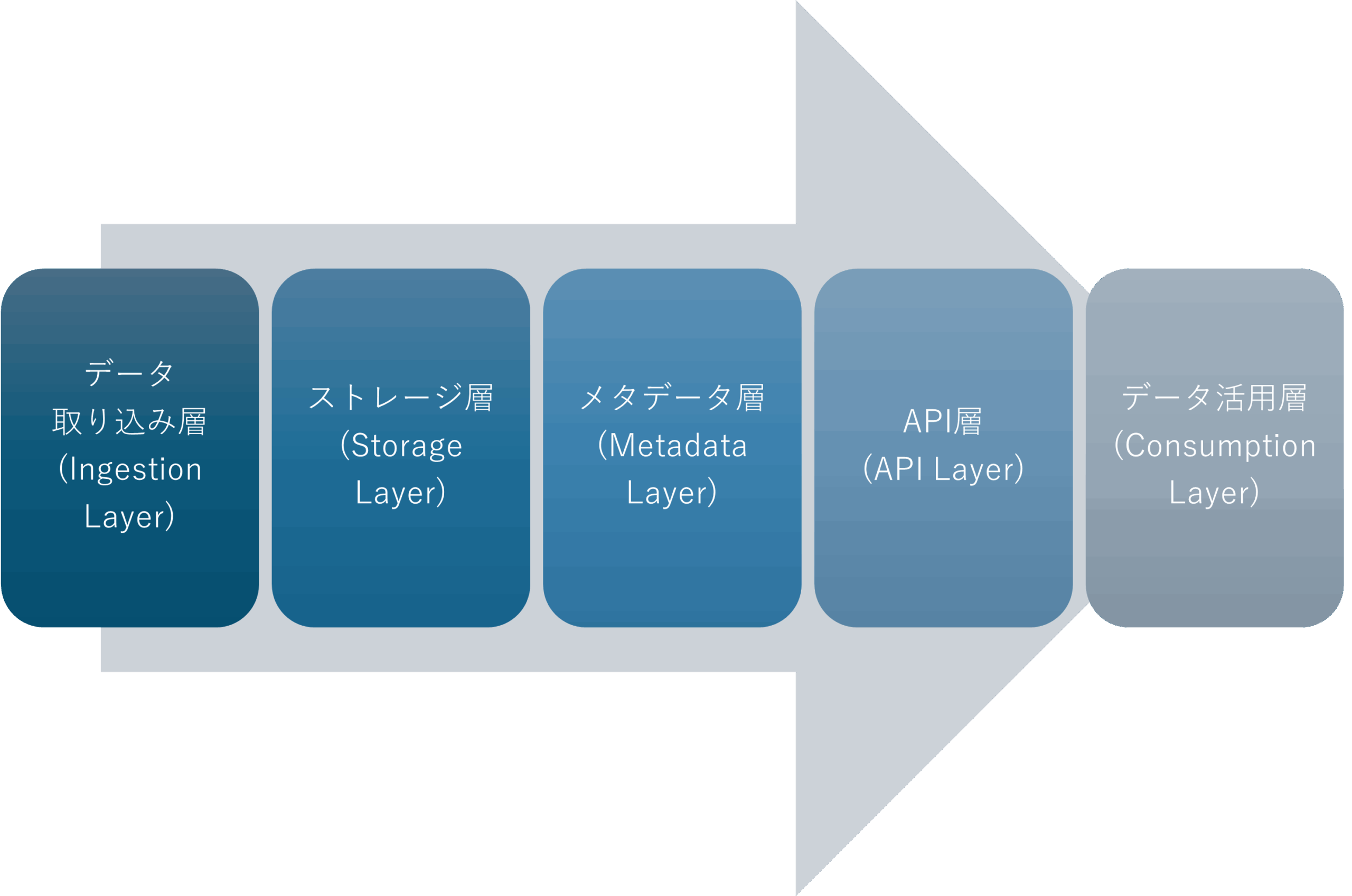
・データ取り込み層 (Ingestion Layer)
ストリーミングデータやバッチ処理によるトランザクションデータなど、様々なソースからデータを取り込みます。多様なプロトコルやツールを通じて、構造化・半構造化・非構造化データに対応します。
・ストレージ層 (Storage Layer)
Parquetのようなオープンなファイル形式を使用し、大量のデータを低コストで保存します。構造化から非構造化まであらゆるデータに対応し、機械学習やAIアプリケーションからも直接アクセスできます。パフォーマンス向上のためには、DELTAやICEBERGのようなパーティション化されたフォーマットが、ファイル圧縮やクエリ最適化の面で有効です。
・メタデータ層 (Metadata Layer)
データレイクハウスにデータウェアハウスのような機能を追加する、心臓部とも言える層です。以下の重要なメタデータを管理します。
– ACIDトランザクション:データの完全性、一貫性、信頼性を確保
– スキーマガバナンス:データ品質を保証
– インデックス:データ検索のパフォーマンスを向上
– キャッシング:頻繁にアクセスされるデータへのアクセスを高速化
– タイムトラベル:過去のデータバージョンへのアクセスや復元を可能に
– アクセス制御:ユーザーベースの権限でデータを保護
・API層 (API Layer)
さまざまなツールやアプリケーションが効率的にデータへアクセスするためのインターフェースを提供します。オープンなデータ形式により、機械学習、高度な分析ツールなどと直接統合でき、多様なユースケースでデータを容易に利用できます。
・データ活用層 (Consumption Layer)
BIツールからの直接アクセス、SQLクエリの実行、機械学習ワークフローなどをサポートし、ビジネスインテリジェンスとデータ分析を実現します。
また、データレイクハウスアーキテクチャはストレージとコンピュートを分離しているため、それぞれを独立して拡張できる柔軟性があります。これにより、ビジネスニーズに応じてリソースを調整し、コストを最適化できます。ワークロードの増大に伴う不要なコストを防ぐためには、コンピュートリソースの使用状況を監視し、最適化することが重要です。
主要データレイクハウスソリューションのご紹介
データレイクハウスを導入するには、Databricksのような「すぐに使える」専用ソリューションを採用する方法と、既存の投資を活用しつつ、異なるアーキテクチャで同様のメリットを提供するベンダーのサービスを組み合わせる方法があります。
Databricks
データレイクハウス分野をリードする企業です。オープンフォーマットのストレージ層である「Delta Lake」は、データレイクに信頼性、セキュリティ、パフォーマンスをもたらします。Delta Lakeはオープンな性質を持つため、AWS、Azure、GCPのいずれのクラウドでも利用可能です。オープンソース技術をベースにしている点も、多くの企業にとって魅力的です。
Snowflake
厳密には伝統的なデータレイクを持ちませんが、独自のマイクロパーティショニング技術により、データレイクハウスアーキテクチャが提供する機能の多くを実現します。ただし、Snowflakeは独自技術(プロプライエタリ)を採用しているため、将来的に他のシステムへ移行する必要が生じた際のハードルが高くなる可能性があります。この独自仕様は「純粋な」データレイクハウスのオープン性とは異なりますが、Snowflake環境内では機能的に同等と言えます。
Azure Synapse Analytics
Azure Data Lakeと組み合わせることで、データレイクハウスの多くの機能を実現します。Synapseは、大規模なデータセットの保存と分析のために設計された、ペタバイト規模のフルマネージド・クラウドデータウェアハウスです。データレイクと接続することでデータレイクハウスに近い機能を提供しますが、これもオープンソースというよりはAzure独自のアーキテクチャとなります。しかし、Snowflake同様、機能的には同等です。
Amazon Redshift
Amazon S3と組み合わせることで、データレイクハウスの機能を実現します。Redshiftもペタバイト規模のフルマネージド・クラウドデータウェアハウスで、S3上のデータに対してクエリを実行し、BIや高度な分析ニーズに応えることができます。他のソリューションと同様、Redshiftも独自技術で構築されており、オープンソースではありませんが、データレイクハウスの主要な機能のほとんどを提供するため、導入を検討する企業にとって有力な選択肢となります。
このリストは全てを網羅したものではなく、他にも多くのベンダーがソリューションを提供しています。また、データレイクハウスのアーキテクチャは、異なるプロバイダーの技術を柔軟に組み合わせることが可能です。例えば、ストレージ層にAmazon S3を使い、メタデータ層にDatabricksのDelta Lakeを組み合わせる、といった構成も実現できます。
データレイクハウスが適しているニーズ?
このようにメリットを持ち合わせるデータレイクハウス。導入に適したニーズをまとめてみます。
1)BIと高度な分析(AI/ML)の両方を実行したい
Power BIやTableauでの定型分析から、機械学習やAIに最適化されたデータセットへのアクセスまで、すべてを単一のシステムで実現できます。
2)データの冗長性を削減したい
複数のデータレイク、ウェアハウス、データマートにデータを複製するのはやめ、すべてを一元管理したい。
3)データ管理の複雑さを軽減したい
データの移動や複雑なパイプラインを最小限に抑え、オープンな単一システムにデータを統合したい。
4)データ管理をシンプルにしたい
多層構造の複雑なアーキテクチャを、管理が容易な単一のソリューションに置き換えたい。
5)データセキュリティを向上させたい
機械学習やAIワークフローを含む、機密データに対するアクセス制御を統一的に適用したい。
6)分析の柔軟性を高めたい
ビジネスニーズの進化に合わせて、ストレージ、メタデータ、活用方法を柔軟に変更したい。
7)ストレージコストを削減したい
CSVから音声、動画まで、あらゆる生データを低コストで保存し、組織の成長に合わせて拡張したい。
データレイクハウスに関する解説をさせていただきました。この記事が、貴社での活用可能性を考える際の参考となれば幸いです。
キーワード
注目の記事一覧
-
 「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
「操作」から「自律」へ:Autonomous Enterpriseを駆動するSAPアーキテクチャ
-
 SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
SAP Jouleが切り拓く「オムニチャネルAI」の未来:AIの価値を決定づけるクリーンコアの絶対性
-
 チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
チャート・グラフvs表。AIによる「オーグメンテッド・インサイト」という最適解
-
 AI Readyへの最短路:なぜ今「クリーンコア」なのか
AI Readyへの最短路:なぜ今「クリーンコア」なのか
-
 ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
ビジネスインテリジェンス(BI)対 ビジネスアナリティクス(BA):意思決定を支える「インサイト」の正体
月別記事一覧
- 2026年6月 (1)
- 2026年5月 (1)
- 2026年4月 (1)
- 2026年3月 (1)
- 2026年2月 (1)
- 2026年1月 (1)
- 2025年12月 (1)
- 2025年11月 (2)
- 2025年10月 (2)
- 2025年9月 (2)
- 2025年8月 (1)
- 2025年7月 (2)